
Technical Analyst Agent™ – Automated Market Intelligence for Chart Analysis, Indicators & Price Action
January 26, 2026
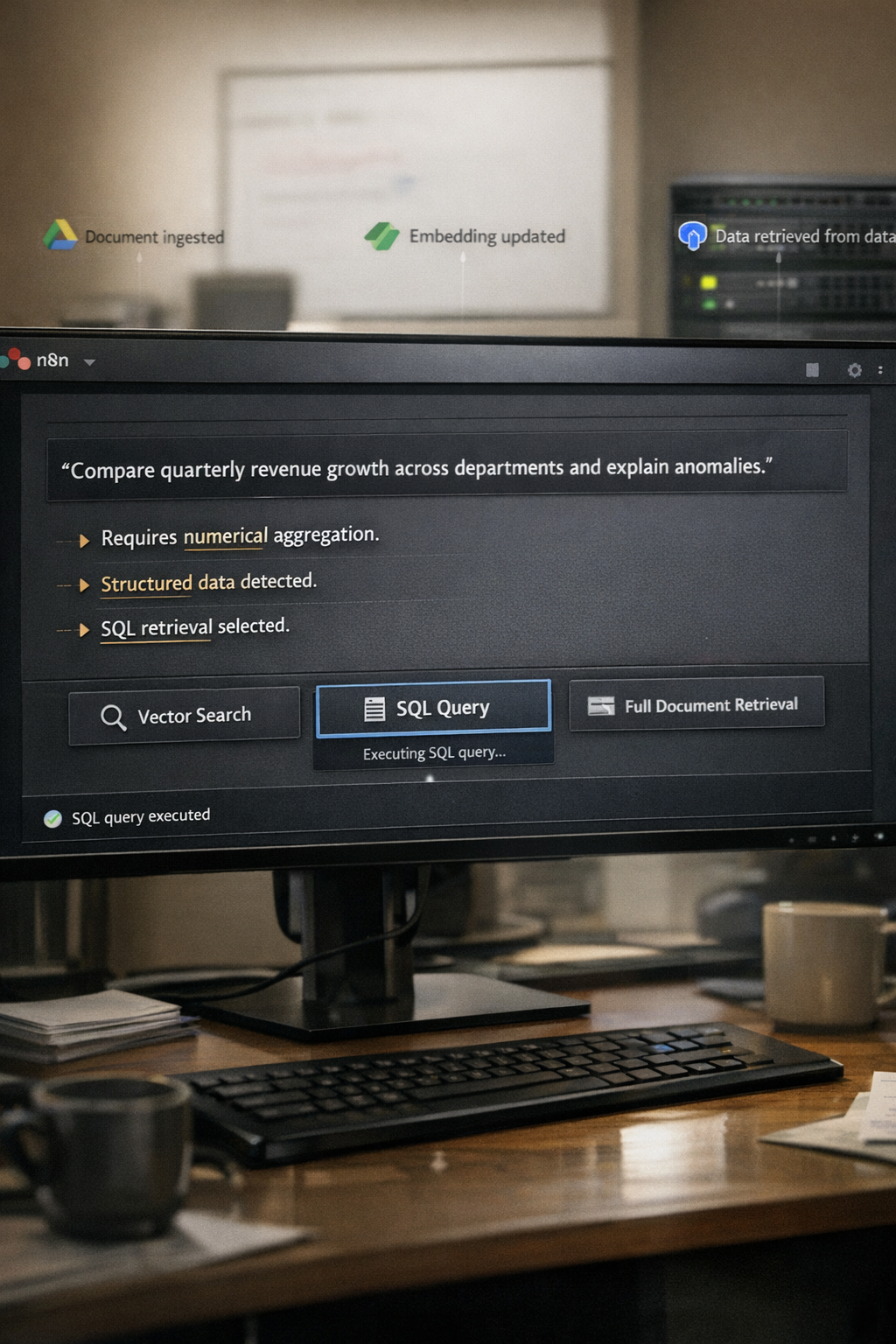
The ability to chat with your data has become a defining capability for modern organizations. Retrieval-Augmented Generation (RAG) made this possible by grounding AI responses in private documents and internal knowledge. However, traditional RAG architectures break down under real-world complexity. They struggle with numerical reasoning, lose critical context through aggressive chunking, and rely on static retrieval strategies that fail to adapt to intent.
To move beyond these constraints, a new paradigm is required: Agentic RAG.
Agentic RAG does not simply retrieve information — it reasons about how information should be retrieved. It behaves like a senior analyst, dynamically selecting the optimal strategy based on the nature of each query. This n8n workflow delivers a production-grade blueprint for such a system, combining OpenAI, Google Drive, Postgres, and Supabase into a unified, autonomous knowledge engine.
A knowledge system is only as strong as its data foundation. This agent eliminates manual ingestion entirely by continuously monitoring a designated Google Drive folder. The moment a document is added or updated, the workflow activates automatically.
A sophisticated routing layer inspects each file type and applies the correct processing logic. PDFs, text documents, and spreadsheets are handled independently and optimally — ensuring accuracy, consistency, and zero manual intervention.
One of the critical failures of basic RAG is its inability to reason accurately over structured data. Agentic RAG solves this through hybrid persistence:
Unstructured Content (PDF, DOCX, TXT)
Content is extracted, intelligently chunked, converted into vector embeddings using OpenAI, and stored in a Supabase vector store for high-performance semantic retrieval.
Structured Data (CSV, XLSX)
Tabular data is preserved inside a Postgres database, enabling exact SQL queries, aggregations, comparisons, and calculations — capabilities vector search alone cannot deliver.
This dual-storage model ensures semantic flexibility without sacrificing mathematical correctness.
At the core of the system is a LangChain-powered agent. This is not a passive retrieval mechanism — it is an active decision-making intelligence layer.
When a query enters via webhook, the agent first determines what kind of answer is required before deciding how to retrieve it. This reasoning step is what elevates the system from RAG to Agentic RAG.
Instead of a single retrieval path, the agent dynamically selects from multiple tools:
Vector Search (Supabase) for conceptual and explanatory queries
SQL Queries (Postgres) for numerical, analytical, and ranking questions
Full-Document Retrieval when broader context is required
This adaptive orchestration enables responses that are context-aware, accurate, and decision-grade.
Traditional RAG retrieves first and reasons later — if at all.
Agentic RAG reasons first, retrieves second.
By combining semantic search, structured querying, and agent-level decision logic, this architecture delivers:
Higher answer accuracy
Reliable numerical reasoning
Deep contextual understanding
Enterprise-grade scalability
This is not a chatbot.
It is an autonomous knowledge system capable of reasoning across your entire document and data ecosystem.
The difference is simple:
Access to information vs. ownership of intelligence.
👉 Get Started Now
 Shopify Order Processor™ – AI-Powered Post-Purchase Automation for CRM, Billing & Email Campaigns
Original price was: $990.00.$77.00Current price is: $77.00.
Shopify Order Processor™ – AI-Powered Post-Purchase Automation for CRM, Billing & Email Campaigns
Original price was: $990.00.$77.00Current price is: $77.00.
 Agentic RAG AI Agent™ – AI Agent for Knowledge Automation, Intelligent Document Querying & Advanced Data Analysis
Original price was: $649.00.$97.00Current price is: $97.00.
Agentic RAG AI Agent™ – AI Agent for Knowledge Automation, Intelligent Document Querying & Advanced Data Analysis
Original price was: $649.00.$97.00Current price is: $97.00.
 TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
 HR & IT Helpdesk Agent™ – AI Agent for Automated Policy Support, Voice Transcription & Intelligent Chat Assistance
Original price was: $916.00.$79.00Current price is: $79.00.
HR & IT Helpdesk Agent™ – AI Agent for Automated Policy Support, Voice Transcription & Intelligent Chat Assistance
Original price was: $916.00.$79.00Current price is: $79.00.
 AI Agent Setup Service™ – Expert Implementation & Environment Configuration for n8n AI Agents
Original price was: $2,497.00.$997.00Current price is: $997.00.
AI Agent Setup Service™ – Expert Implementation & Environment Configuration for n8n AI Agents
Original price was: $2,497.00.$997.00Current price is: $997.00.
 YouTube Repurposing Engine™ – Automated Blog Conversion Blueprint
Original price was: $227.00.$137.00Current price is: $137.00.
YouTube Repurposing Engine™ – Automated Blog Conversion Blueprint
Original price was: $227.00.$137.00Current price is: $137.00.
 TikTok Intel System™ – Automated Data Extraction Blueprint
Original price was: $257.00.$147.00Current price is: $147.00.
TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
TikTok Intel System™ – Automated Data Extraction Blueprint
Original price was: $257.00.$147.00Current price is: $147.00.
TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
 DM Sales Engine™ – High-Converting Lead Message Framework
Original price was: $127.00.$67.00Current price is: $67.00.
DM Sales Engine™ – High-Converting Lead Message Framework
Original price was: $127.00.$67.00Current price is: $67.00.
 InvoiceFlow™ – Automated Billing & Invoice Management System
Original price was: $287.00.$167.00Current price is: $167.00.
Shopify Order Processor™ – AI-Powered Post-Purchase Automation for CRM, Billing & Email Campaigns
Original price was: $990.00.$77.00Current price is: $77.00.
Agentic RAG AI Agent™ – AI Agent for Knowledge Automation, Intelligent Document Querying & Advanced Data Analysis
Original price was: $649.00.$97.00Current price is: $97.00.
TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
HR & IT Helpdesk Agent™ – AI Agent for Automated Policy Support, Voice Transcription & Intelligent Chat Assistance
Original price was: $916.00.$79.00Current price is: $79.00.
AI Agent Setup Service™ – Expert Implementation & Environment Configuration for n8n AI Agents
Original price was: $2,497.00.$997.00Current price is: $997.00.
YouTube Repurposing Engine™ – Automated Blog Conversion Blueprint
Original price was: $227.00.$137.00Current price is: $137.00.
TikTok Intel System™ – Automated Data Extraction Blueprint
Original price was: $257.00.$147.00Current price is: $147.00.
TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
DM Sales Engine™ – High-Converting Lead Message Framework
Original price was: $127.00.$67.00Current price is: $67.00.
InvoiceFlow™ – Automated Billing & Invoice Management System
Original price was: $287.00.$167.00Current price is: $167.00.
InvoiceFlow™ – Automated Billing & Invoice Management System
Original price was: $287.00.$167.00Current price is: $167.00.
Shopify Order Processor™ – AI-Powered Post-Purchase Automation for CRM, Billing & Email Campaigns
Original price was: $990.00.$77.00Current price is: $77.00.
Agentic RAG AI Agent™ – AI Agent for Knowledge Automation, Intelligent Document Querying & Advanced Data Analysis
Original price was: $649.00.$97.00Current price is: $97.00.
TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
HR & IT Helpdesk Agent™ – AI Agent for Automated Policy Support, Voice Transcription & Intelligent Chat Assistance
Original price was: $916.00.$79.00Current price is: $79.00.
AI Agent Setup Service™ – Expert Implementation & Environment Configuration for n8n AI Agents
Original price was: $2,497.00.$997.00Current price is: $997.00.
YouTube Repurposing Engine™ – Automated Blog Conversion Blueprint
Original price was: $227.00.$137.00Current price is: $137.00.
TikTok Intel System™ – Automated Data Extraction Blueprint
Original price was: $257.00.$147.00Current price is: $147.00.
TikTok Caption Engine™ – Bulk Upload Automation Framework
Original price was: $117.00.$57.00Current price is: $57.00.
DM Sales Engine™ – High-Converting Lead Message Framework
Original price was: $127.00.$67.00Current price is: $67.00.
InvoiceFlow™ – Automated Billing & Invoice Management System
Original price was: $287.00.$167.00Current price is: $167.00.


